Important disclaimer: For your own benefit you should never run random commands you find on the internet, this is why whenever I tell you to run a command, immediately after I will let you know exactly what it does. Feel free to check the documentation of the command to be sure I am not lying to you.
This is a follow up of the quick entry I made previously on how to put metadata on your LaTeX generated documents.
Introduction
In this tutorial I will tell you how to do three things:
Anonymise your PDF files removing rubbish metadata and optimize them for loading
Write useful metadata to help file organization
Rename files based on the metadata you consciously wrote
If you want to see more about why metadata is important you can read this [2 min], and if you want to see why is important to not have more meta information in your files than necessary, then read this [5 mins].
If you do not care about any of that, then why are you reading this?
Requirements
The programs
exiftool,pdftkandqpdfSome
.pdffiles to work with
Bear in mind that I have only tried this on a Linux machine. Chances are, this works on any other OS since all the tools above are available for any OS, but that is for you to figure out.
Anonymise your files
To anonymise files I stole the code from this gist and this blog entry, huge thanks to these people for sharing.
There they explain what each tool does, but on the spirit of self-containment I will let you know what we achieve with this:
Remove/update objects that contain information in the
.pdffileRemove the pointers to the objects
Linearise your file for fast web loading
#!/bin/sh
# make it a function (optional)
clean(){
# pdftk dumps data from a file
pdftk $1 dump_data | \
# select all the lines starting with (InfoValue)
# and the next to it
sed -e 's/\(InfoValue:\)\s.*/\1\ /g' | \
# remove what sed just retrieved
pdftk $1 update_info - output clean-$1
# remove all tags and create a new file with the
# prefix "clean-"
exiftool -all:all= clean-$1
# print tags
exiftool -all:all clean-$1
# remove embeded stuff
exiftool -extractEmbedded -all:all clean-$1
# linearize and save in a new file with the prefix "clean2-"
qpdf --linearize clean-$1 clean2-$1
# these just print metadata
pdftk clean2-$1 dump_data
exiftool clean2-$1
pdfinfo -meta clean2-$1
}
# you can add this loop for this to just put the file in the
# directory you want it to run and then run it (optional)
for FILE in *; do clean $FILE; done
Okay, if you take this snippet as it is, you need to:
Create a file, say you called it
pdfcleanMove it to the directory where you have all your
.pdffilesMake it executable with
chmod +x pdfcleanAnd run it by typing
./pdfclean
That is what I recommend doing, because as you can tell, the function is made to run over a single file, and that is why you need to loop at the end.
Other options are to take the function
clean()and put it into your.bashrc,.zshrc.profileor wherever your shell stuff loads, and then you will be able to runclean <name of your file>.pdfjust as a normal shell command. I would recommend calling the function something more memorable though.
So, now you have anonymised files! Yay!
Oh! One more thing. As you saw, the snippet above will create three additional files for each file that you processed, which most likely you do not want. So, I recommend moving everything except for the files with the prefix
clean2-to some directory that you can call./unclean/or whatever. I have not removed the creation of additional files because is good to have backups, but you can do it if you live life to the fullest and do not care for data loss.
Write useful metadata to your files
So, we want to create a .csv because is an easy way to save tags for files, and we will make use of exiftool which can write tags from .csv files.
The first thing we need to do is to get the names of all our files. There are different way to do this, you just need to be in the directory where your files are and
run
exiftool -SourceFile -csv . > tags.csv,or
ls > tags.csvand then make the name of the column inside the fileSourceFile
The first (and better) option can be used instead of the option
-commonor without any, in order to load more metadata, but I don not find that useful because makes the file more messy, your choice.
Suppose you used the first option (such a smart individual you are) it will create a .csv that uses comma as a separator (duhh), but you do not want that. Use something odd enough that it cannot be confused with a character in the name of your files, something like ^, @, character that is not used commonly while writing, I will use ^.
This can be done in any text editor with search and replace functionality, or you could use any spreadsheet software to make it, be ware that spreadsheet software can do nasty stuff sometimes.
I do, however, recommend to use any spreadsheet software to add all the tags you want. Or a text editor is fine too.
If you use a spreadsheet software to deal with your .csv file, just remember to tell it what to use as separator, in the case of LibreOffice Calc you should have a pop up window like this:
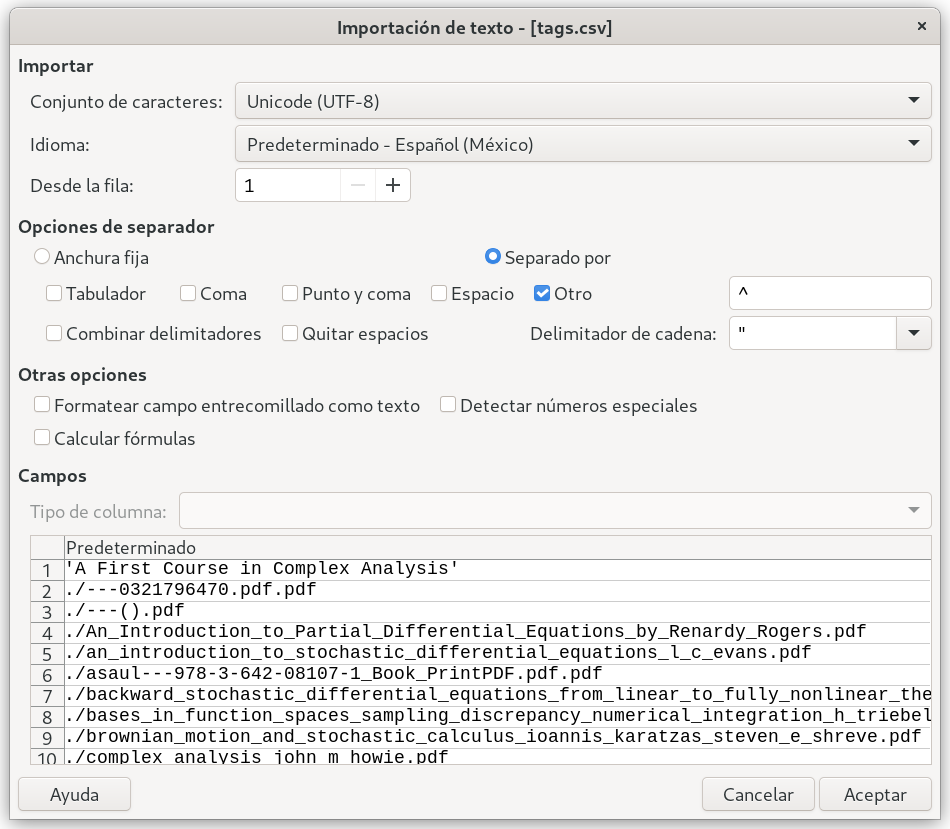
Calc pop up
And then you will have a file like this:
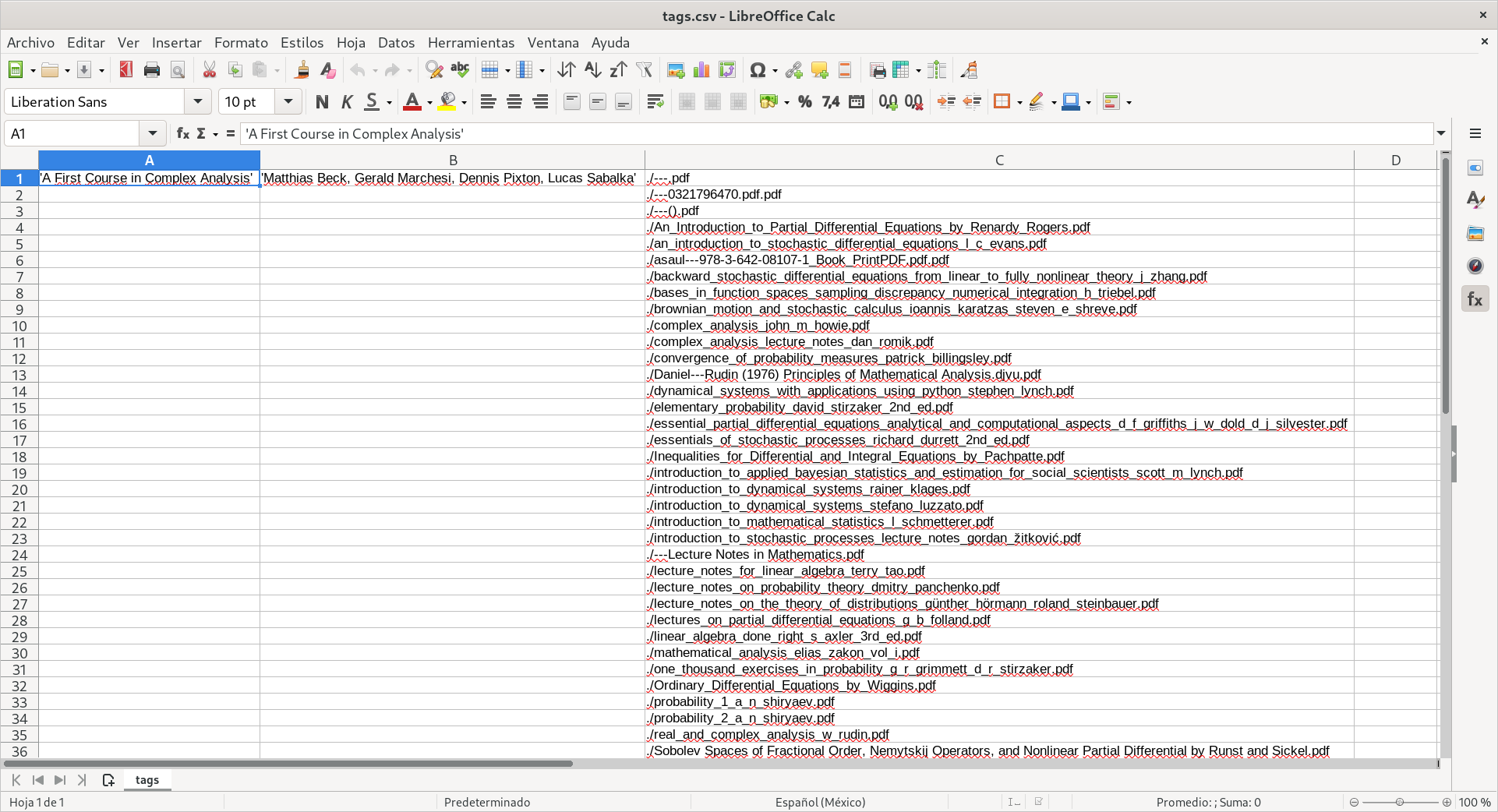
Calc file
Actually if you have followed the tutorial, the third column on that image will be for you in the first column and will have the name
SourceFile, this image is just for illustrative purposes.
So here comes the tedious part, you will have to add to your csv file all the tags you want, to have in the metadata. I only want title and author, probably edition is useful. IDK, do as you please but remember that this is clerical work and there is no way to escape it if you want to benefit from having useful meta information in your files.
This is why you must add metadata to your files.
Remember to put the name of tags you want in the first row.
Now that you have your .csv just check if some of your tags have weird characters or spaces, and if so, make sure to deal with that appropriately. By weird characters I mean anything that can mean something for the shell, because we want to use the metadata to rename files. Remember?
Now everything is ready, so you just need to run
exiftool -csv=tags.csv -csvDelim ^ .
In this case exiftool will use your beautiful .csv file with the option -csv=tags.csv, then -csvDelim ^ tells it to use ^ as separator, and the dot . is indicating to scan the current directory.
And now you have nicely labelled pdf files! Brilliant!
One thing to note. I mention to be careful of weird characters in your tags…well sometimes you will have actually weird characters in your title or some other tag. For instance you might have a totally legal copy of the book Measure, Integration & Real Analysis by Sheldon Axler, and you can see that it has a
&in the title. Well it is likely you want to deal with those cases separately for the sake of simplicity.
Rename files using metadata
Now, finally got to the point that make me do all these things: Renaming files using metadata.
Well, since you already have nicely tagged files you only need to run
exiftool '-filename<$author---$title.%e' .
And PUFF! Just like that, like magic, exiftool will change the SourceFile and FileName tags using the option -filename giving it the author, and title tags, and the extension of the file with %e to all the files in the directory, this the dot . at the end. And of course, not only will change the tags, but also will rename them.
And that is it, you can of course you can backup your tags by using again exiftool -csv . > tags.csv and then you can manage them from there since the only thing you need to do to update your files now is to use the command above.
Future work
In my obsession to have proper means of organization for my resources, I want to create some kind of PDF manager, and I already have a couple of ideas.
What I want is to use the basic tools that I have used here to have a program that is listening to some directories and notify of changes on them for you to add the metadata and rename the files. Similar to what Zotero does.
It can potentially make use of identifiers such as DOI, ISBN and such, but need to think properly about that because obviously the metadata from there is rather contaminated and also can be bad. If you do not believe me it can be bad, just download a book directly from the Springer site (if you University has that kind of access and you can do it for free) and run exiftool on that, you will see.
Listening to what happens in directories must be easy enough, since I am planning to do this for Linux first and there we have events for it, as you can see here.
Also I want something that is triggered both if you add files in the command line or graphically, and that it prompts the interface of the program either in the command line or on a graphic window accordingly.
As per recommendation of EL DAVID I plan to prototype in shell and use Python for the project. Also I want to use GTK-4 because we are no more in the XII century.
But anyway, those are some ideas.
Will update on that regard when I start I guess.
Other updates, personal things too
If you use several editors to work on projects with LaTeX or perhaps you have collaborators, you might find extremely annoying that each editor or person has their own mind and have decided that indentation is a matter of taste. And since it is actually (in many cases) a matter of taste, I want to create some small program with
AWKto fix that stuff, and make your documents to your own taste. I reckon this might be unnecessary to do, because I am sure I can achieve what I want in half a second using Vim, but it is still a good little practice run for development using some other language.Tomorrow I will go to Bologna to present a poster in the Third Italian Meeting on Probability and Mathematical Statistics, so I hope to post some pictures about that next weekend.
And finally I decided to go back to do music. Particularly when I am back in Leeds I plan to buy a guitar and start learning classical guitar the right way, I am pretty excited about that. Also, have been recently experimenting with my voice to sing Mexican and Latin American traditional songs, so there is that. Do not think I will share that online anytime soon but anyway.